
Cet article va inspecter de plus près les problèmes et solutions liés aux Microdata et RDFa et pourquoi un simple problème n'est pas si simple.
Introduction
Tout d'abord, essayons de comprendre pourquoi nous avons besoin de données structurées telles que les Microdata et RDFa ainsi que leurs utilisations. Supposons que vous avez une page web contenant le mot «Jaguar» à l'intérieur du contenu. Un être humain qui est en train de lire l'article peut comprendre en fonction du contexte si le mot «Jaguar» identifie un animal ou une marque de voiture. Malheureusement, les machines (ordinateurs) ne peuvent pas encore comprendre automatiquement la différence, car elles ne connaissent pas le contexte dans lequel les mots sont utilisés. C'est la raison pour laquelle nous insérons des données structurées manuellement afin de fournir des informations contextuelles sur notre contenu. Cela signifie que l'homme a besoin d'ajouter manuellement des informations supplémentaires pour expliquer à une machine le sujet de la page !
Pourquoi avons-nous besoin que les machines connaissent le sujet de la page ? Une des raisons est que les moteurs de recherche tels que Google utilisent cette information pour afficher des Rich Snippets dans les SERP (Search Engine Result Page).
Problèmes
Pour ajouter manuellement des données structurées, vous devez avoir des connaissances en HTML, SEO (Search Engine Optimisation) et Microdata / RDFa, mais tout le monde ne peut pas avoir ces compétences. Des utilisateurs avec des rôles différents ont des compétences différentes. Maintenant, analysons tous les problèmes et voyons comment nous pouvons automatiser l'ajout de ce type d'information.
Problème 1 :
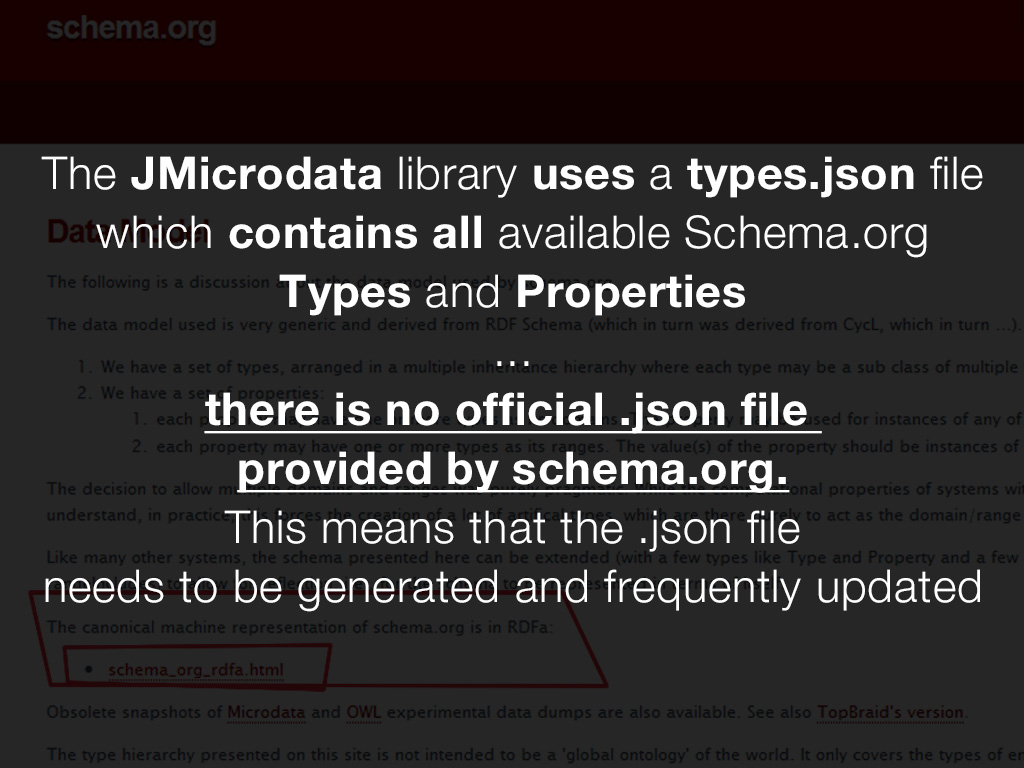
La bibliothèque JMicrodata utilise un fichier types.json qui contient tous les Types et Propriétés de Schema.org
...
Il n'existe aucun fichier .json officiel fourni par schema.org.
Cela signifie que le fichier .json doit être généré et mis à jour régulièrement.
Afin de générer des sémantiques valides (car nous ne voulons pas créer de catastrophe à chaque amélioration), nous avons besoin d'une base de données quelque part pour vérifier si le code sémantique est valide. Une base de données peut être un fichier .json compressé contenant tous les types et propriétés disponibles et fournis par schema.org. En fait, c'est ce que JMicrodata fait - la bibliothèque utilise un fichier .json contenant tout afin de vérifier la validité de la sémantique, et ce fichier est généré avec le bot Spider4Schema.
Malheureusement, il n'y a pas de fichier .json officiel fourni par schema.org, mais ils sont dessus. Pour le moment, le fichier doit être généré manuellement. Un autre problème est que, depuis que schema.org est un nouveau standard, ses spécifications sont fréquemment mises à jour, ce qui signifie que les fichiers types.json doivent être générés et mis à jour fréquemment.
Problème 2 :
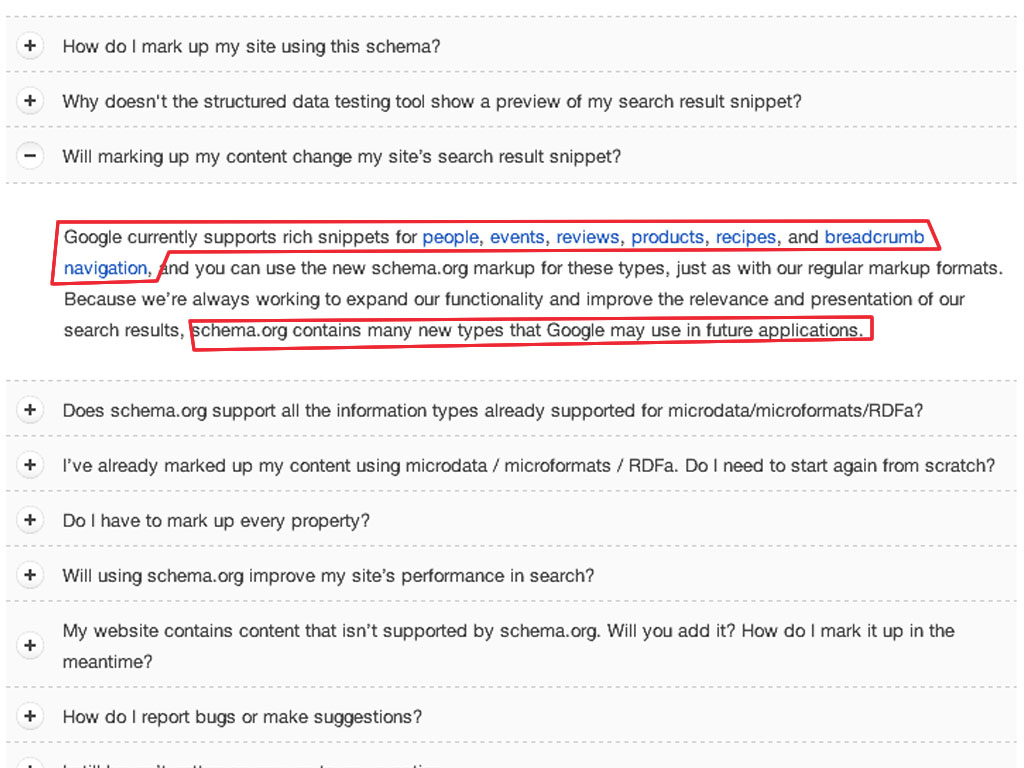
Google prend actuellement en charge les rich snippets pour les personnes, évènements, revues, produits, recettes, et les fils d'ariane. Mais ils travaillent sur de nouveaux types. L'histoire est la même pour Yandex, Bing et Baidu, ils ne supportent que certains d'entre eux. Donc, en bref, pour le moment, nous n'avons pas besoin de supporter tous les types disponibles.
Problème 3 :
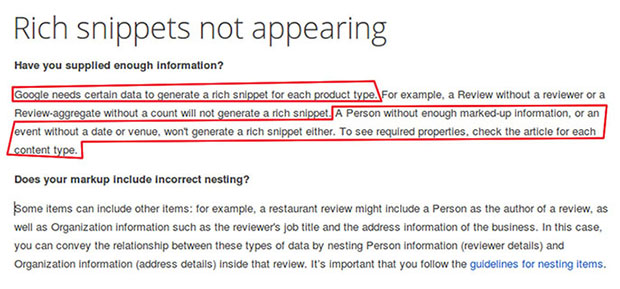
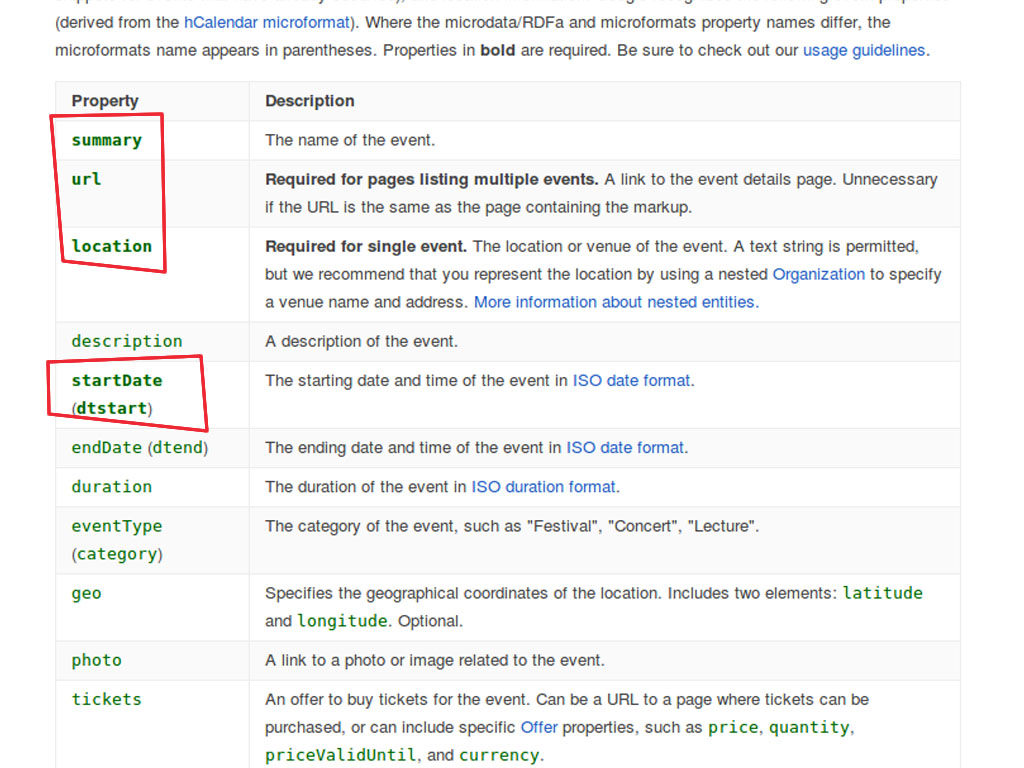
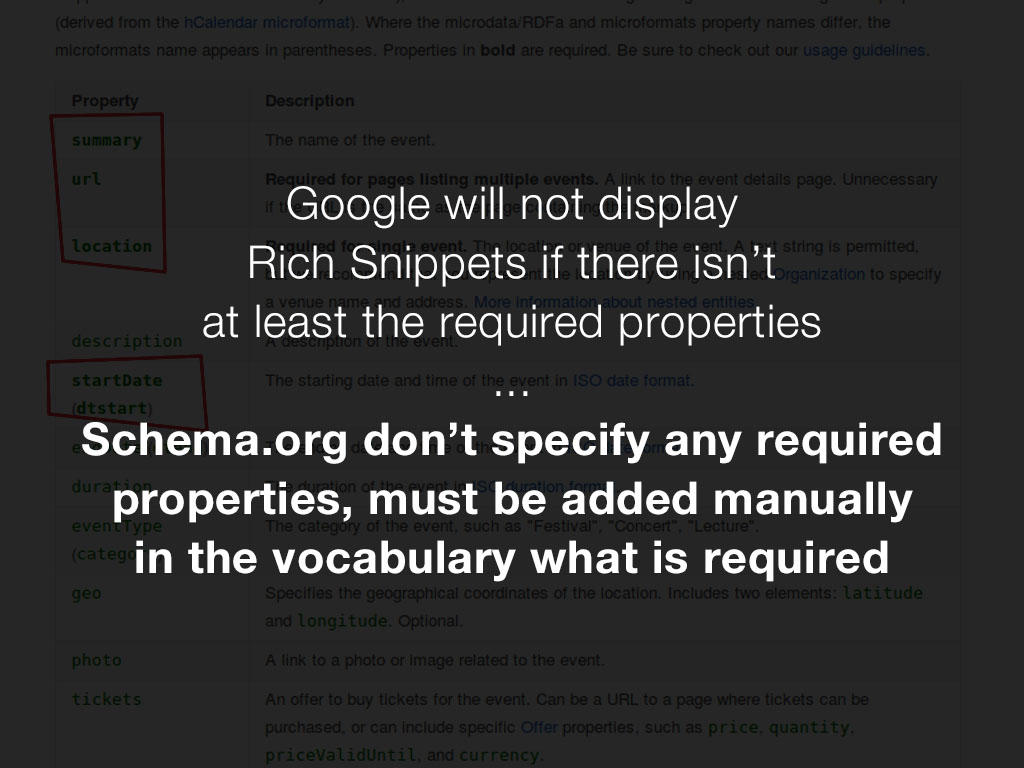
Google a besoin de certaines données pour générer un extrait enrichi (rich snippet) pour chaque type pris en charge. Il n'affichera pas de rich snippets si les propriétés obligatoires ne sont pas présentes. Malheureusement, schema.org ne fournit aucune de ces propriétés nécessaires et n'est pas normalisé.
Si nous implémentons des données structurées, nous voulons nous assurer que les extraits enrichis apparaissent : nous devons donc veiller à ce que les données obligatoires soient fournies. Pour réduire la probabilité que cela se produise, nous devons nous assurer que lorsqu'un éditeur enregistre un article, les propriétés obligatoires minimales requises sont fournies. Pour voir et vérifier les propriétés obligatoires, nous avons besoin de les renseigner quelque part, comme le fichier types.json. De cette façon, nous avons besoin de spécifier manuellement celles qui sont nécessaires dans le fichier types.json car Google ne fournit aucune API pour récupérer cette liste automatiquement. C'est également le cas pour d'autres moteurs de recherche.
Problème 4 :
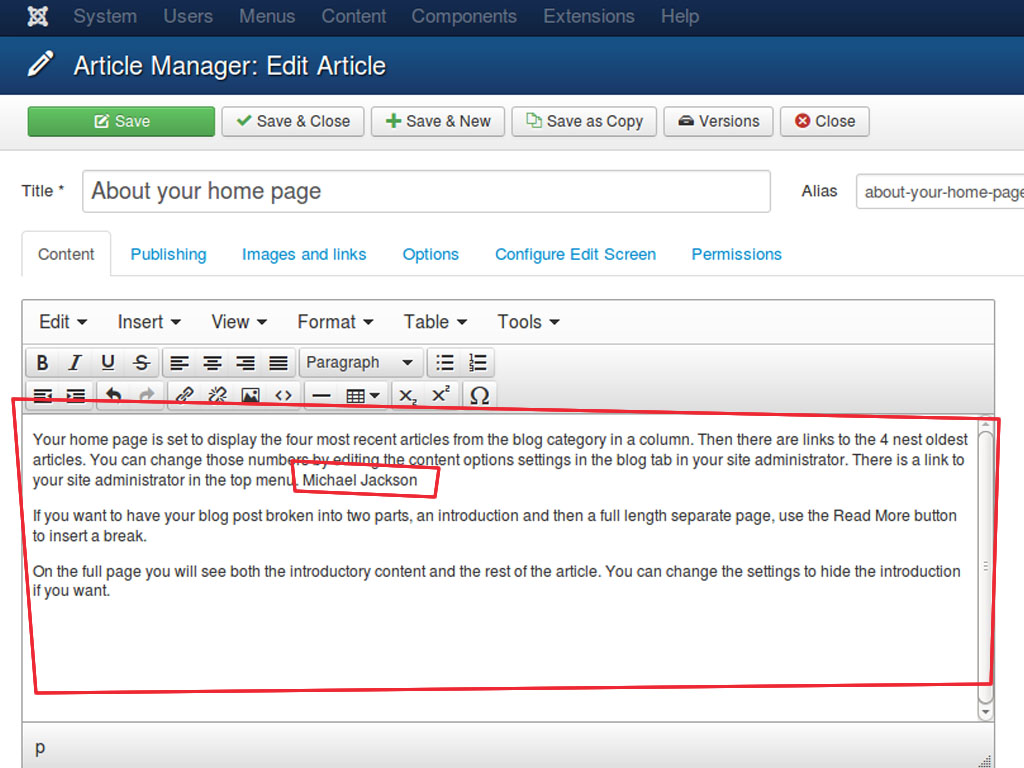
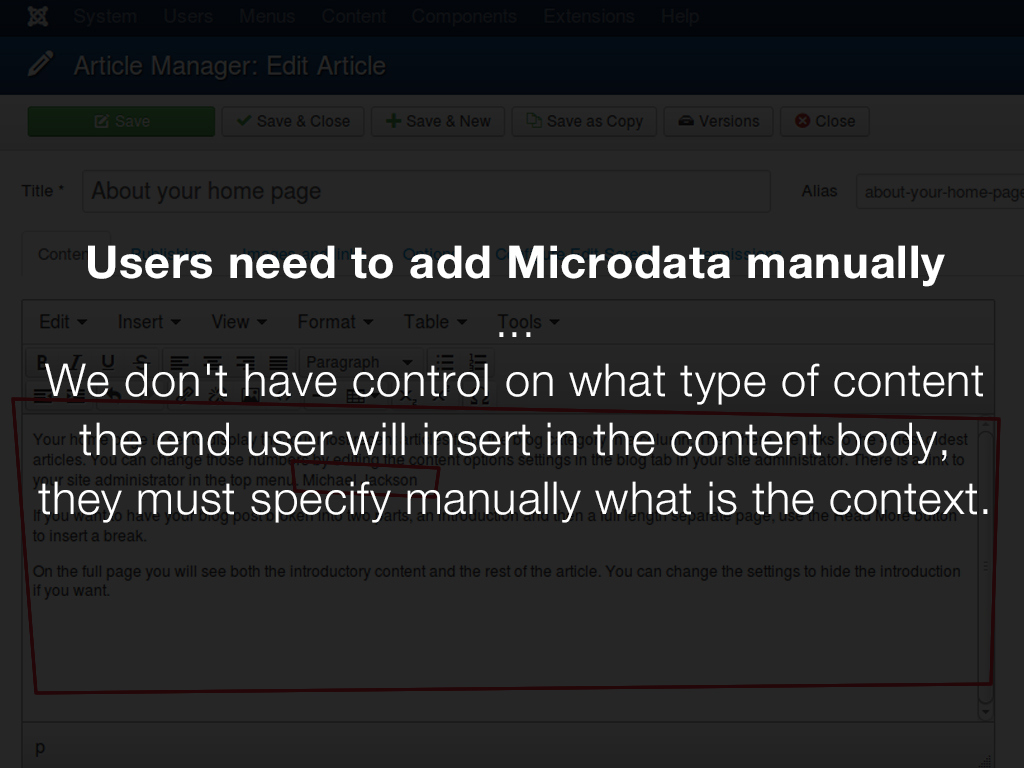
Comme mentionné au début de l'article, des êtres humains doivent ajouter des informations supplémentaires manuellement pour expliquer aux machines de quoi parle une page. Même si nous pouvons automatiser ce processus en partie, il y a des points que nous ne pouvons pas contrôler, comme l'éditeur de contenu. Nous n'avons pas de contrôle sur le type de contenu que l'utilisateur final va insérer dans le corps du contenu. Ils doivent spécifier manuellement quel est le contexte.
Résumé rapide :
Il n'y a pas de solution miracle pour générer totalement les données structurées (Microdata, RDFa) de façon automatique. Actuellement, il n'y a pas vraiment de standard, chaque moteur de recherche supporte quelques types et nécessite certaines propriétés obligatoires afin d'afficher des extraits enrichis, et Schema.org n'en fournit aucun.
C'est une technologie récente, qui s'améliore de jour en jour et qui nécessite des mises à jour fréquentes.
Solutions
Même s'il n'est pas possible d'automatiser entièrement la génération des données structurées (Microdata, RDFa), celle-ci peut être faite partiellement en utilisant la bibliothèque JMicrodata, qui vous permet d'afficher une sémantique valide et qui offre un système de fallbacks pour changer le type de page dynamiquement. Mais cette bibliothèque n'est pas forcément facile à utiliser et intuitive.
Grâce à une idée de Thomas Hunziker, un plug-in pour Joomla 3.2 et versions ultérieures a été créé pour simplifier l'utilisation de la bibliothèque JMicrodata dans le CMS. Fondamentalement, le plugin analyse le code HTML et convertit les attributs data-* HTML5 dans la sémantique des Microdata. Les attributs data-* sont nouveaux dans HTML5, ils nous donnent la possibilité d'intégrer des attributs de données personnalisés à tous les éléments HTML. Donc, si vous désactivez la bibliothèque, le code HTML sera encore valide.
Vous pouvez télécharger et trouver la documentation du plugin ici.
(Vous pouvez également télécharger et essayer le même plug-in avec la nouvelle version de la bibliothèque de Microdata, qui contient une bibliothèque JRDFa. Ainsi, avec un seul bouton, vous pouvez tout simplement passer des Microdata au RDFa Lite 1.1)
La syntaxe à utiliser est simple :

Vous pouvez utiliser cet attribut HTML5 data-sd partout : dans vos vues, templates, éditeur d'articles, partout où vous êtes autorisé à modifier le code HTML.
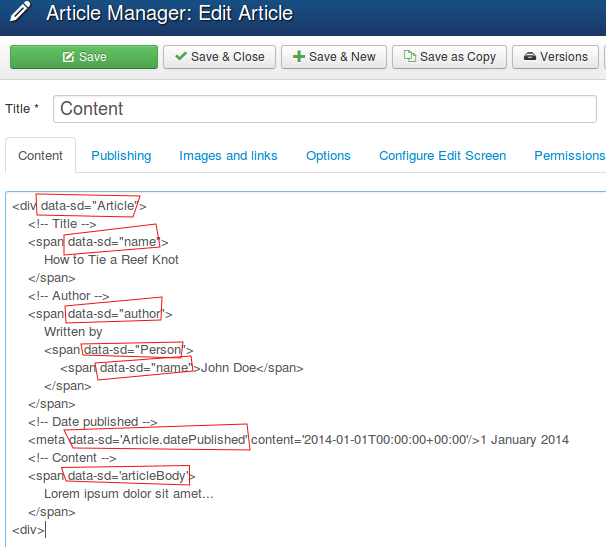
Avant d'afficher la page web, le plugin recherche les attributs data-sd et les remplace par la sémantique de Microdata générée.
Actuellement ce plugin ne supporte pas les fallbacks et certains suffixes data-*, mais cela devrait évoluer comme suit :

Ce qui permettra d'ajouter des fallbacks et des suffixes personnalisés à rechercher et convertir, de sorte que tout développeur tiers puisse ajouter et utiliser son propre suffixe. Mais cette solution est encore complexe pour quelqu'un qui n'est pas expert en HTML et dans le domaine des Microdata/RDFa.
Maintenant, je travaille sur une implémentation proposée par YouJoomla.com, qui pour le moment n'est pas encore implémentée, mais qui ne devrait pas tarder à arriver ! Ci-dessous, une présentation très simple de cette implémentation :
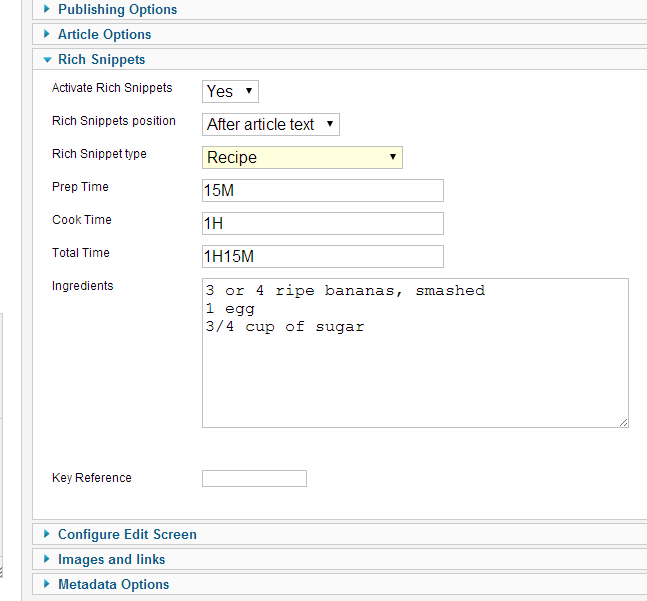
Dans les options de l'article, il vous suffit de sélectionner l'un des types pris en charge par Google et de remplir les propriétés. De plus, si vous utilisez cette fonction, vous ne serez pas autorisé à enregistrer le contenu avant d'insérer les champs obligatoires requis par Google. De cette façon, les rich snippets seront affichés dans les SERP.
Depuis le frontend, voici comment cette information sera affichée :
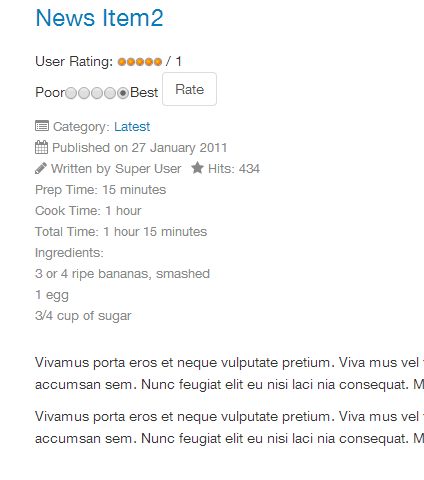
Conclusion
En utilisant les deux implémentations, les éditeurs pourront ajouter des données structurées d'une manière simple, et les développeurs pourront utiliser l'API dans leurs propres extensions. Il reste du travail à accomplir et beaucoup de discussions et d'expérimentations sont déjà en cours. La nouvelle version de la bibliothèque prend en charge la sémantique RDFa afin de pouvoir choisir entre les Microdata et RDFa. De plus, il y a un plugin système qui vous permet d'utiliser et d'ajouter des données structurées. Aucune sortie n'a encore été plannifiée, mais à la fin du programme GSoC 2014, de nouvelles mises à jour seront proposées pour être insérées dans le cœur du projet.




